





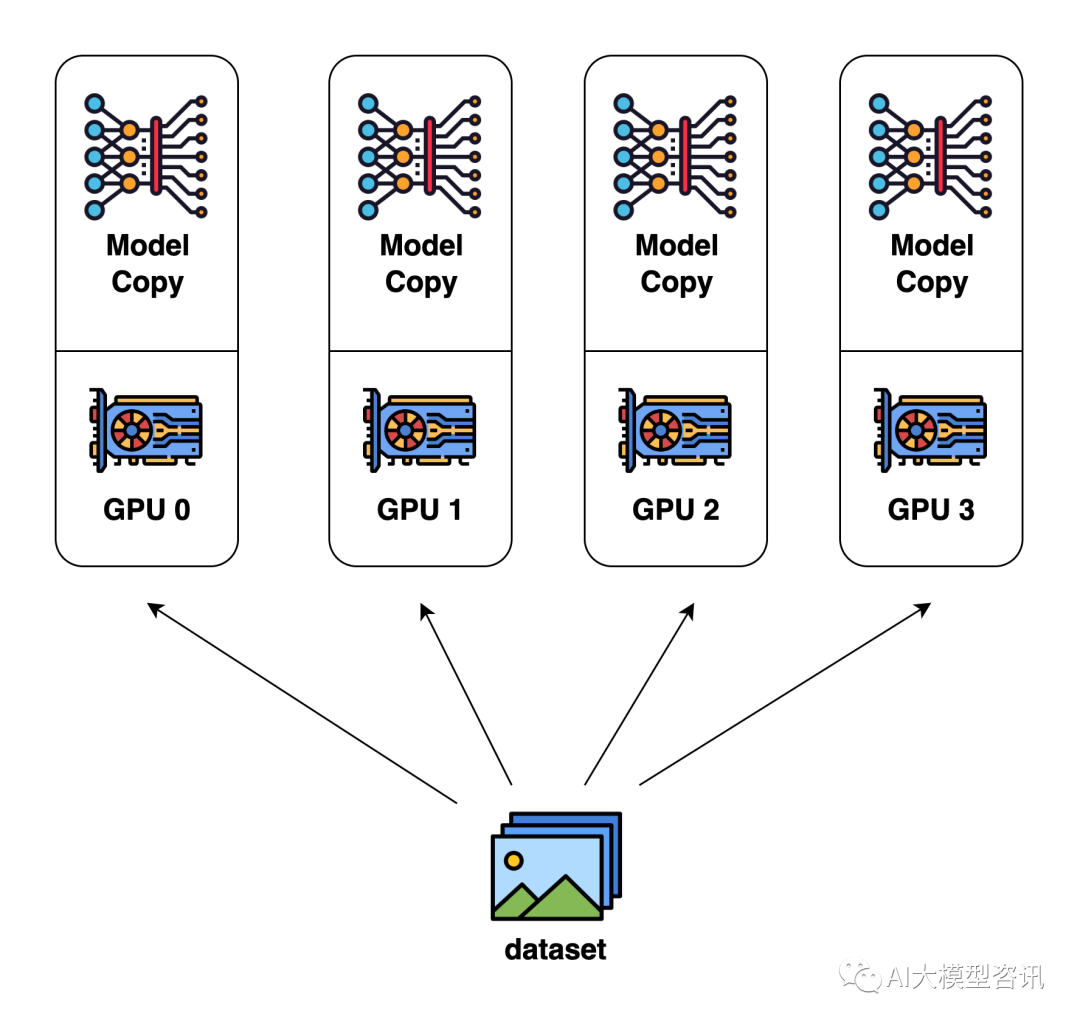
- 数据并行
数据并行是指将数据集划分成多个子集,然后将这些子集分发到不同的计算设备上,每个设备上都拥有模型的完整副本。每个设备独立地计算其子集上的梯度,然后将梯度汇总(例,平均)以更新模型的参数。
特点为:数据集分割;每个设备模型权重完整;梯度计算独立,但参数更新同步或异步地
- 张量模型并行
模型并行是指将模型本身划分成多个部分,然后将这些部分分发到不同的计算设备上,每个设备负责计算模型的一部分。输入数据通常会在所有设备之间流动,经过每个设备上的部分模型计算。
特点为:数据流动;每个设备负责一部分权重;需要考虑通信开销
- 流水线并行
流水线并行是模型并行的一种特殊形式,它将模型的各层划分成多个阶段,每个阶段分发到不同的计算设备上。输入数据会依次经过每个阶段的计算,类似于流水线作业,可以实现较高的并行度,因为不同阶段可以在不同设备上同时处理不同的数据批次。
特点为:模型需要层次分明;依次计算;并行度较高;
并行策略地选择取决于具体地应用场景、模型大小一级硬件资源等因素,实际情况中也可以结合多种并行策略来达到最优性能,比如DeepSpeed地ZeRO,就是结合了数据并行与模型并行地优点。

Comments | NOTHING